30th September 2024
Kumud Tripathi summarises paper titled Attention Is Not Always the Answer: Optimizing Voice Activity Detection with Simple Feature Fusion co-authored by Chowdam Venkata Kumar, and Pankaj Wasnik accepted in Main Track at the 26th edition of the Interspeech 2025 Conference | August 17-21, 2025.
Introduction
Voice Activity Detection (VAD) identifies speech segments in audio and plays a crucial role in enhancing speech technologies like ASR, speaker recognition, and virtual assistants. Traditional VAD approaches, relying on acoustic features such as MFCC and energy thresholds, struggle in noisy, real-world settings. Modern deep learning methods using CNNs and RNNs improve robustness but depend heavily on large labeled datasets. Recently, pre-trained models (PTMs) like wav2vec 2.0, HuBERT, WavLM, UniSpeech, MMS, and Whisper have shown promise by leveraging vast unlabeled data to learn robust speech representations. Although PTMs have demonstrated success in VAD through fine-tuning, little is known about why they work well or how they compare with traditional features like MFCC. This work conducts a detailed comparison and proposes feature fusion strategies. Results on datasets such as AMI and VoxConverse show that combining MFCC and PTM features, especially via simple methods like concatenation, improves VAD performance over complex fusion techniques.
The key contributions of this work are as follows:

Fig. 1: Overview of the FusionVAD Framework with Different Feature Fusion Strategies.
Results:
Performance of Voice activity detection with and without feature fusion is shown in Table 1. From the results, it shows that Whisper outperforms other models in VAD. MFCCs have higher FAR but lower MR than most PTMs, suggesting they capture noisy speech, while PTMs reduce FAR but miss some speech. This indicates MFCC and PTM features carry complementary information that can enhance performance when fused.
Table 1: Performance (in %) of Voice activity detection with and without feature fusion. *Bold represents the best result.

Table 2: Comparison (in %) of best performing fusion model with baseline Pyannote.

Figure 1 shows that simple fusion methods like concatenation and addition yield speech segment boundaries closer to ground truth, while cross-attention performs inconsistently. This supports the idea that VAD benefits more from lightweight fusion strategies than complex, parameter-heavy methods like cross-attention.
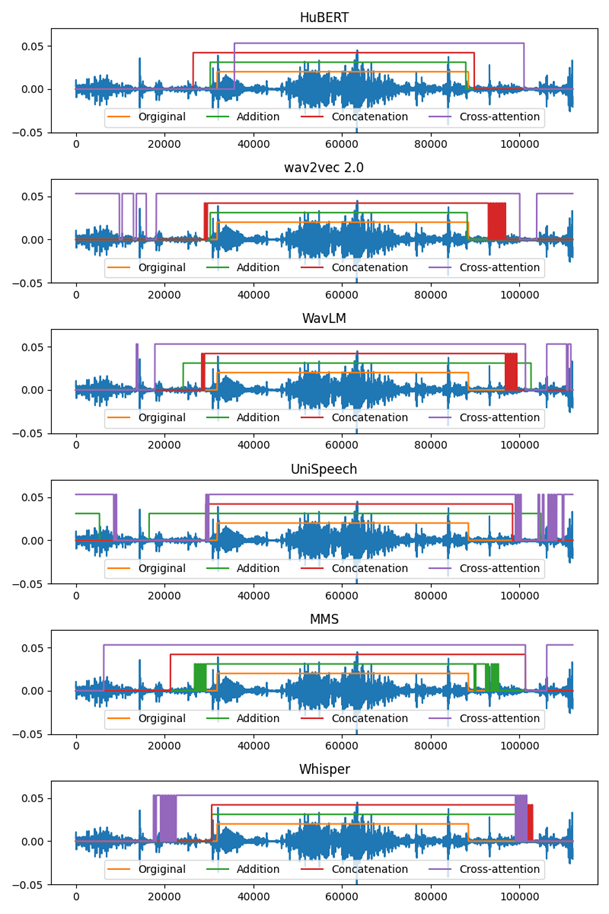
Figure 1: Feature fusion outputs (Green: Addition, Red: Concatenation, and Purple: Cross-Attention) along with the original reference (Yellow) for all FusionVAD models on a single audio segment from the AMI file ”EN2004a”.
This study shows that combining MFCC and PTM features using simple fusion methods like addition and concatenation significantly improves VAD performance. Addition performs best in most cases, while cross-attention adds complexity without benefit. The best fusion model outperforms Pyannote by 2.04% DER, proving lightweight methods are both effective and efficient. These results suggest that simple strategies can enhance performance in other speech tasks without increasing computational cost.
@article{tripathi2025attention,
title={Attention Is Not Always the Answer: Optimizing Voice Activity Detection with Simple Feature Fusion},
author={Tripathi, Kumud and Kumar, Chowdam Venkata and Wasnik, Pankaj},
journal={arXiv preprint arXiv:2506.01365},
year={2025}
}
To know more about Sony Research India’s Research Publications, visit the ‘Publications’ section on our ‘Open Innovation’s page: Open Innovation with Sony R&D – Sony Research India
In most of the cases, it has been found that Content Driven sessions outperform the time driven sessions. The results are obtained on 6 baselines: STAMP, NARM, GRU4Rec, CD-HRNN, Tr4Rec on datasets like Movielens (Movies), GoodRead Book, LastFM (Music), Amazon (e-commerce).