Aditya Srinivas Menon*, Raj Prakash Gohil*, Kumud Tripathi, Pankaj Wasnik
30th September 2024
Raj Prakash Gohil summarizes paper titled LASPA: Breaking Language Barriers in Speaker Recognition with Prefix-Tuned Cross-Attention co-authored by Aditya Srinivas Menon, Raj Prakash Gohil, Kumud Tripathi and Pankaj Wasnik accepted at the 26th edition of the Interspeech 2025 Conference | August 17-21, 2025.
Imagine a world where your voice unlocks your devices, regardless of the language you speak. Speaker recognition systems are everywhere—from smart assistants to security systems. But what happens when you switch languages? Traditional systems often stumble, confusing language-induced changes in your voice of a different person.
LASPA: a novel approach that disentangles speaker identity from language, enabling robust, language-agnostic speaker recognition—even when you switch between languages.
Speaker recognition models extract “embeddings”—compact representations of your voice. But these embeddings often mix up two things:
When you speak a different language, your voice changes—not because you’re a different person, but because the language demands different sounds and rhythms. Traditional models can’t always tell the difference, leading to errors.
LASPA (Language Agnostic Speaker Disentanglement with Prefix-Tuned Cross-Attention) introduces a joint learning strategy that separates speaker and language information.
Key Innovations

Fig. 1: Block-diagram of the propose approach in Diffusion-based Voice Conversion
Step-by-step:
Datasets Used:
Performance Metrics
RESULTS:

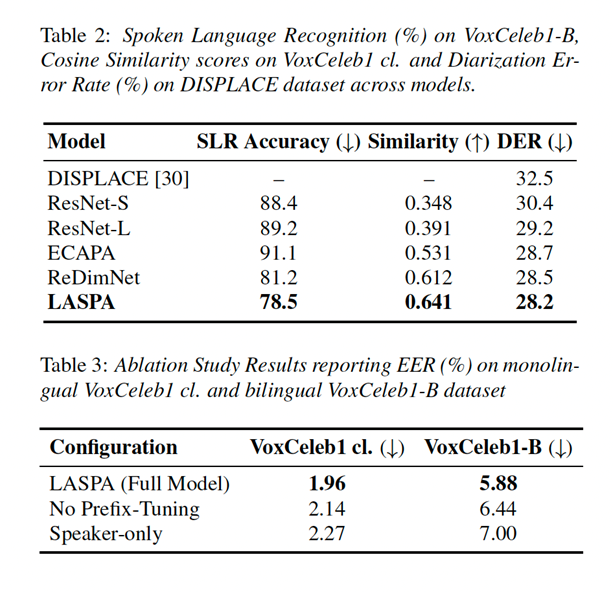
LASPA is a leap forward for speaker recognition in our multilingual world. By disentangling speaker and language information using prefix-tuned cross-attention, it delivers robust, efficient, and language-agnostic performance.
What’s next? The authors plan to further refine prefix-tuning and explore its applications in speaker verification and related tasks.
@misc{menon2025laspalanguageagnosticspeaker,
title={LASPA: Language Agnostic Speaker Disentanglement with Prefix-Tuned Cross-Attention},
author={Aditya Srinivas Menon and Raj Prakash Gohil and Kumud Tripathi and Pankaj Wasnik},
year={2025},
eprint={2506.02083},
archivePrefix={arXiv},
primaryClass={cs.SD},
url={https://arxiv.org/abs/2506.02083},
}
In most of the cases, it has been found that Content Driven sessions outperform the time driven sessions. The results are obtained on 6 baselines: STAMP, NARM, GRU4Rec, CD-HRNN, Tr4Rec on datasets like Movielens (Movies), GoodRead Book, LastFM (Music), Amazon (e-commerce).