By Abhinav Thorat, Research Engineer at Sony Research India
29th March 2023
Human beings are curious by nature, and it is our curiosity that made us what we are today. But the fundamental question that drives the curiosity is the question ‘Why?’.
Why we do somethings, why things happen and what could have happened so on and more interestingly why do we ponder on the question of why?.
Causal Inference is essentially the method of inferring causes from data. If we have enough observational data, we can infer causes from that data, but it is not that simple and gets complicated as we go in-depth. But why must we go away from statistical analysis where we have enough methodologies for understanding correlation? The reason is that Correlation is not Causation

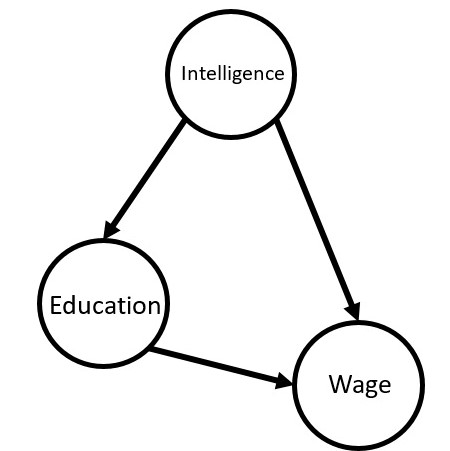
Directed Acyclic Graph
Since we have the ability to intervene in the data-driven world, we can carry out counterfactual regression where we can estimate the effect of treatment (Intervention) on an outcome by comparing what would have happened if same group had not been treated.
This brings us to Potential outcomes framework. To wrap our heads around this, we will talk in terms of potential outcomes. They are potential because they didn’t happen. Instead, they denote what would have happened in the case some treatment was taken. We sometimes call the potential outcome that happened, factual, and the one that didn’t happen, counterfactual.
As for the notation, we use an additional subscript:
Y_i0 is the potential outcome for unit(i) without the treatment.
Y_i1 is the potential outcome for the same unit(i) with the treatment.

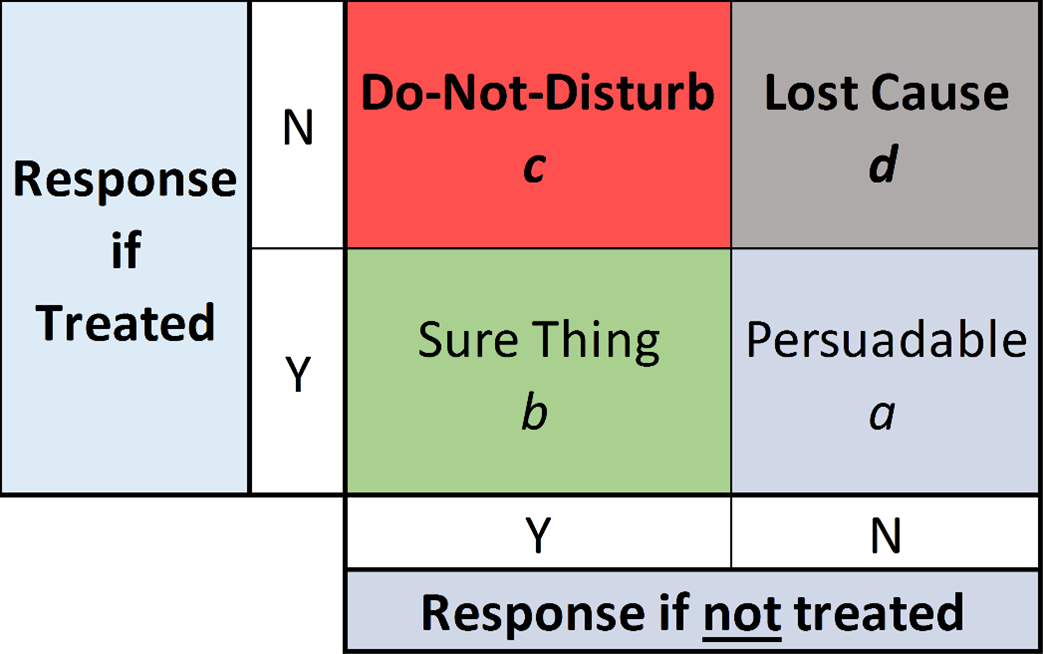
Uplift modelling
Causal Inference from Machine Learning perspective by Brady Neal, 2020