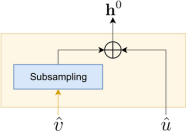
We conducted experiments on Librispeech-100 and Tedlium2 datasets, with different choices for the SSL model. Overall, we found that our approach shows a significant WER reduction, despite only a minor increase in the model’s size.
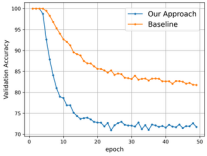
As depicted in Figure 4, the utilization of the SSL representation leads to rapid convergence, and we observe our model outperforming the baseline with only a few epochs of training.
Despite reducing the size of the encoder by 80% (specifically, decreasing the number of encoder layers from 12 to only 2), we find that our model continues to outperform the baseline by a significant margin.
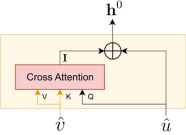
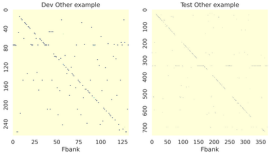
Finally, Figure 5 illustrates the attention scores originating from our fusion layer based on cross-attention. It is interesting to note that the attention ultimately focused solely on capturing the nearby information despite having the ability to access the entire representation. This implies that the local context holds greater significance in the context of this fusion. In addition, this cross-attention block can now be utilized to obtain the alignment between both representations.