By Nirmesh J. Shah, Senior Research Scientist at Sony Research India
29th March 2023
Collaborative Background: In Sony Research India, we are given opportunities to work and collaborate with experts across global Sony Group of Companies. Being the experts in developing speech technologies for Indian languages, we explored the opportunity to forge a close collaboration with Dr.Naoya Takahashi, one of the leading experts in the audio/speech domain in Sony Group Corporation, Japan to develop an Emotional Voice Conversion system.
Emotional voice conversion (EVC) system converts the emotion of a given speech signal from one style to another,without modifying the linguistic content of the signal. EVC technology has potential applications in movie dubbing, conversational assistance, cross-lingual synthesis, etc.
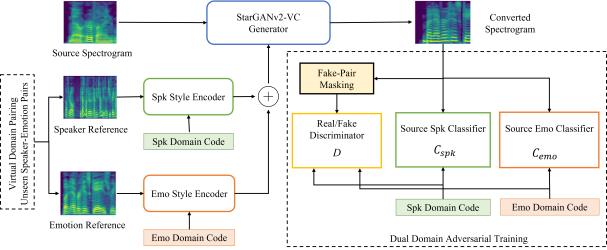
Figure 1: Block diagram of the proposed EVC-USEP architecture.
We presented our results on Hindi emotional database. Demo audio samples can be found online.
URL: https://demosamplesites.github.io/EVCUP/
We have conducted two subjective tests, namely, mean opinion scores (MOS) and ABX test to evaluate the quality of converted voices and evaluation of emotion conversion, respectively. For objective evaluation, we use an emotion classification network to evaluate the accuracy of emotion conversion and speaker similarity scores. From both objective and subjective evaluations, we confirm that the proposed method successfully converts the emotion of the target speakers,
outperforming the baselines w.r.t. emotion similarity, speaker similarity, and quality of the converted voices, while achieving decent naturalness.
Table 1: Subjective and objective evaluations results. MOS are shown for quality along with margin of error corresponding to 95% confidence interval.
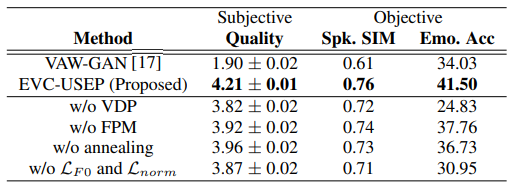
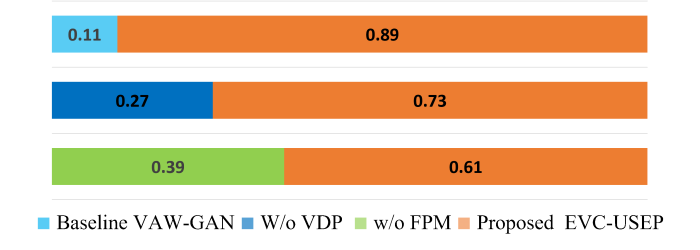
Figure 2: ABX Subjective Evaluation for Emotion Similarity.
To know more about Sony Research India’s Research Publications, visit the ‘Publications’ section on our ‘Open Innovation’s page: