Abhinav Thorat, Ravi Kolla, Niranjan Pedanekar
30th September 2024
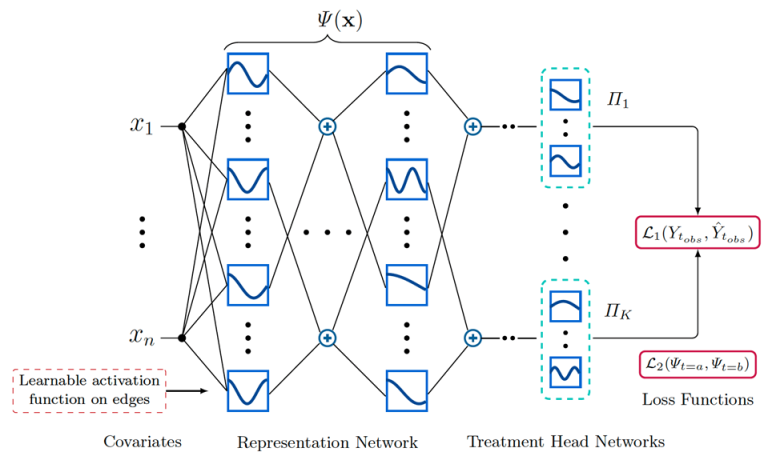
Figure 1: Overview of the proposed KANITE architecture
Ravi Kolla summarizes the paper titled “KANITE: Kolmogorov-Arnold Networks for ITE estimation” co-authored by Abhinav Thorat, Ravi Kolla and Niranjan Pedanekar, accepted at European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases – ECML PKDD 2025.
Introduction
In causal inference, the estimation of Individual Treatment Effects (ITEs) is a foundational problem, as it is crucial for understanding the impact of a treatment on an individual user and personalizing treatments. ITE estimation has applications across a wide range of domains including healthcare, education, e-commerce, entertainment, and the social sciences. Despite its wide range of applications, ITE estimation remains challenging due to the absence of ground truth data, confounding factors, and treatment assignment bias. To overcome these issues, we propose new ITE estimation algorithms built on the recently popularized Kolmogorov–Arnold Networks.
In the below we summarize the key contributions of work:
Proposed Model: KANITE
Few Key Results
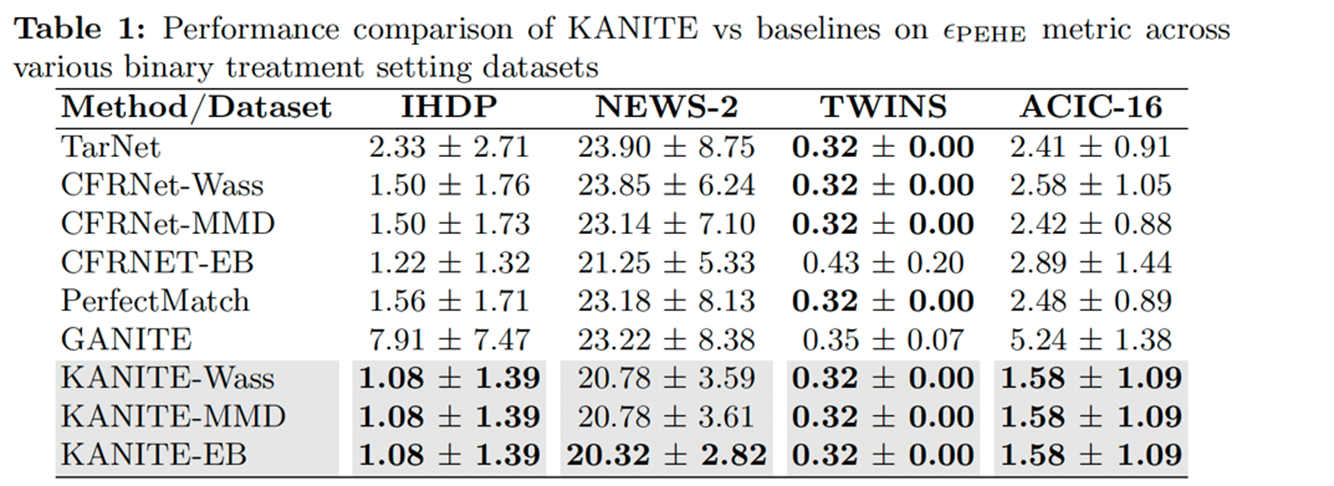
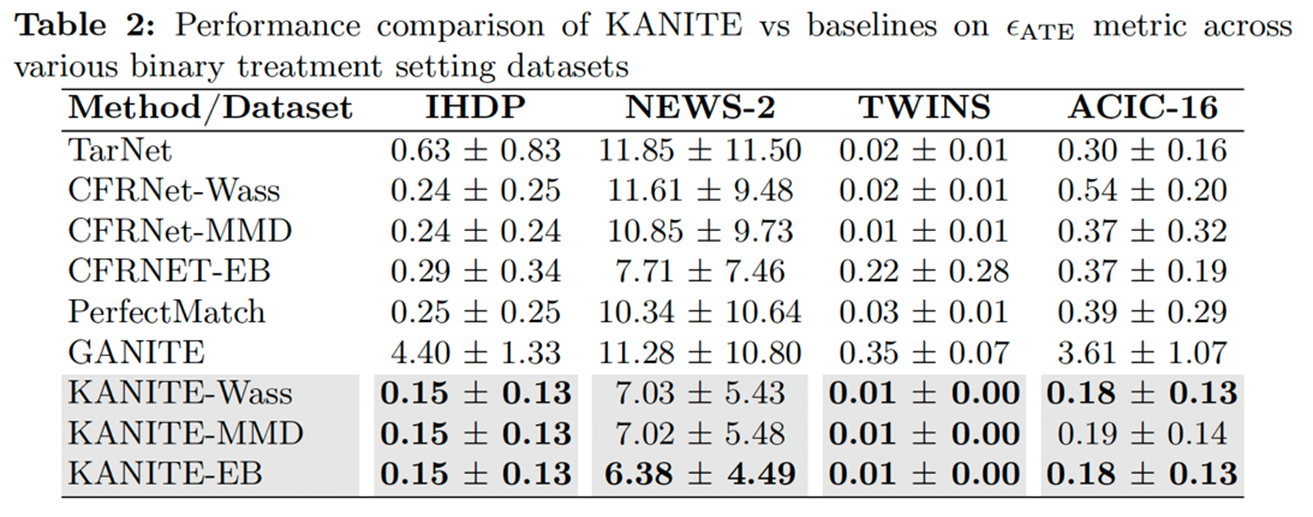
KANITE is a state-of-the-art framework for ITE estimation that leverages shared representation learning using either IPM or Entropy Balancing. Unlike traditional MLP-based architectures, KANITE employs KANs as its backbone, enabling it to learn more accurate causal effect estimates. The framework introduces three algorithms—KANITE-MMD, KANITE-Wass, and KANITE-EB—each utilizing a different IPM or Entropy Balancing-based representation loss to ensure balanced covariate representations across treatment groups. Experimental results demonstrate that KANITE effectively handles multipletreatmentscenarios, outperforming all considered baselines. Furthermore, KANITE achieves superior parameter efficiency and faster convergence while maintaining strong counterfactual prediction capabilities.
To know more about Sony Research India’s Research Publications, visit the ‘Publications’ section on our ‘Open Innovation’s page: Open Innovation with Sony R&D – Sony Research India
In most of the cases, it has been found that Content Driven sessions outperform the time driven sessions. The results are obtained on 6 baselines: STAMP, NARM, GRU4Rec, CD-HRNN, Tr4Rec on datasets like Movielens (Movies), GoodRead Book, LastFM (Music), Amazon (e-commerce).