Summarizing ‘Precise Event Spotting in Sports Videos: Solving Long-Range Dependency and Class Imbalance’
Sanchayan Santra, Vishal Chudasama, Pankaj. W, Vineeth N Balasubramanian
30th September 2024
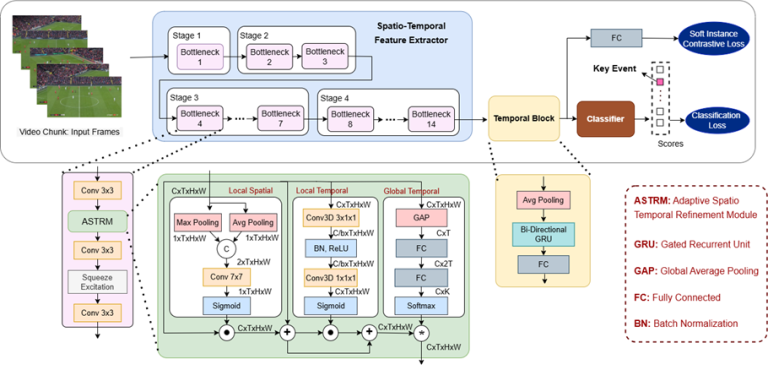
Fig. 1: Overview of proposed framework
The framework composed of a spatio-temporal feature extractor and a temporal block for capturing long-range dependency before the classifier. In each bottleneck block we add ASTRM after the first conv. ASTRM further enhances the features with local spatial, local temporal and global temporal information. The network is trained with Soft-IC loss in addition to the classification loss to handle class imbalance.
Vishal Chudasama summarises paper titled Precise Event Spotting in Sports Videos: Solving Long-Range Dependency and Class Imbalance co-authored by Sanchayan Santra, Pankaj. W, Vineeth N Balasubramanian accepted at the CVPR 2025 | June 2025
Introduction:
Precise Event Spotting methods aim to predict an event at the exact frame it occurs (e.g., goal, boundary). This is crucial for generating game summaries, finding specific events, and editing lengthy matches. However, it poses significant challenges and require a deep understanding of the game and its key events. Existing PES methods mainly face two challenges. First is the long-range temporal dependency that arises due to the nature of events. To predict the event frames, observing just the nearby frames does not suffice; several other potentially distant frames need to be observed to predict the event correctly. Second, there is an inherent imbalance in the number of samples among the classes. Some events naturally occur more frequently than others. Existing methods prefers features extracted from pretrained networks and transformer-based temporal modules for the prediction. But transformers does not work well with long videos. On the other hand, the issue of sample imbalance among classes has not been addressed properly in the literature.
To address these issues, we introduce three-way approach:
We proposed an end-to-end framework using a CNN-based spatio-temporal feature extractor and GRU-based temporal network to achieve precise event spotting while addressing long-range dependency and class imbalance.
In the spatio-temporal feature extractor, we introduce Adaptive Spatio-Temporal Refinement Module (ASTRM), which enhances the features with spatial and temporal information.
We also introduce Soft Instance Contrastive (Soft-IC) loss to enforce compact features and improve class separability, addressing the class imbalance issue.
Key Results:
To validate our proposed model, we evaluated on various sports benchmark datasets i.e., SoccerNet-V2, Tennis, FineGym, Figure Skating and non-sports dataset such as Fine Action.
Table 1: Result Comparison on SoccerNet-V2 datasets in terms of mAP tight and loose settings. Best- and second best-performing measures are highlighted with bold font and underline font, respectively
Model
Params (M)
GFLOPs
mAP-Tight
mAP-Loose
Baidu (TF)
—
—
47.05
73.77
SpotFormer
—
—
60.9
76.1
E2E-Spot (RegNet-Y 200MF)
4.46
39.61
61.19
73.25
E2E-Spot (RegNet-Y 800MF)
12.64
151.4
61.82
74.05
Spivak
17.46
461.89
65.1
78.50
ASTRA
44.33
8.83
66.63
78.14
T-DEED (RegNet-Y 200MF)
16.36
21.96
39.43
52.93
T-DEED (RegNet-Y 800MF)
46.22
60.25
21.57
30.49
UGLF
4.46
39.61
63.51
73.98
COMEDIAN (ViSwin-T)
70.12
222.76
71.33
77.07
Proposed
6.46
60.25
73.74
79.11
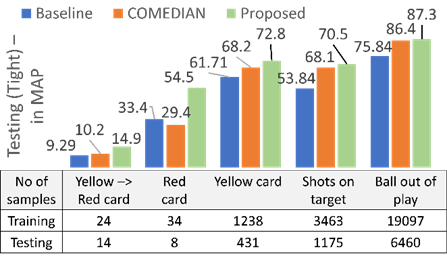
Fig. 2: Per class score analysis on a few classes of SoccerNetV2 dataset in tight setting.
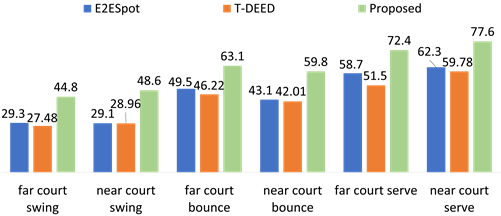
Fig. 3: Per-class score comparison on δ=0 setting in terms of mAP on the Tennis dataset.
Fig. 4: Per-class score comparison on δ=0 setting in terms of mAP on the Figure Skating dataset.
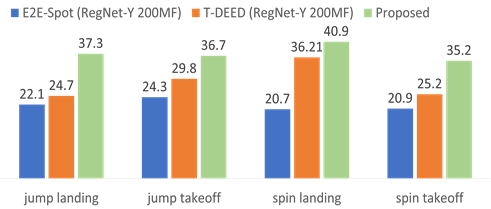
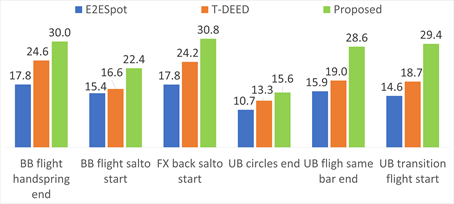
Fig. 5: Per-class score comparison on δ=0 setting in terms of mAP on the FineGym dataset.
Conclusion:
This paper proposes an end-to-end network for precise spotting of events in sports videos. It effectively tackles the long-range dependency and class imbalance issues and outperforms existing methods. To this extent, we introduce a new ASTRM module for enhancing spatio-temporal features. Further, to address the class imbalance issue, we propose Soft-IC loss, which enforces compact features and improves class separability. We further employed ASAM during training to ensure the model performs well on unseen data. While our method has advanced the state-of-the-art, especially in the more challenging cases with a relatively simple design, there is further scope for improvement on the two fronts we tried to address. Certain larger networks can improve the performance further but at the cost of computation. On the other hand, the spatial and temporal resolution at which the data is being processed will likely have an impact. The precise spotting may become easier with increased resolution, but it increases the processing burden.
In most of the cases, it has been found that Content Driven sessions outperform the time driven sessions. The results are obtained on 6 baselines: STAMP, NARM, GRU4Rec, CD-HRNN, Tr4Rec on datasets like Movielens (Movies), GoodRead Book, LastFM (Music), Amazon (e-commerce).