30th September 2024
Nirmesh Shah summarises paper titled, “REWIND: Speech Time Reversal for Enhancing Speaker Representations in Diffusion-based Voice Conversion”, co-authored by Ishan Biyani, Nirmesh Shah, Ashishkumar Gudmalwar, Pankaj Wasnik and Rajiv Ratn Shah, accepted at the 26th edition of the INTERSPEECH conference.
Introduction
Speech time reversal refers to the process of reversing the entire speech signal in time, causing it to play backward. Such signals are completely unintelligible since the fundamental structures of phonemes and syllables are destroyed. However, they still retain tonal patterns that enable perceptual speaker identification despite losing linguistic content. In this paper, we propose leveraging speaker representations learned from time reversed speech as an augmentation strategy to enhance speaker representation. Notably, speaker and language disentanglement in voice conversion (VC) is essential to accurately preserve a speaker’s unique vocal traits while minimizing interference from linguistic content.
To address the limitations of the conventional speaker representations in VC, we introduce following components:

Fig. 1: Block-diagram of the propose approach in Diffusion-based Voice Conversion
Results:
Demo samples are available on our Demo Page.
We initially conducted perceptual studies to determine whether speaker identity is retained in time-reversed speech signals. Total 25 participants participated in it. We found that subjects could identify the correct speaker with 80.3% accuracy from the time reversed speech signals. Corresponding confusion matrices for the perceptual study is shown in Figure 2.

Figure 2: Confusion matrices for the perceptual study of speaker identification from the time reversed speech. Here, M1, M2, M3 and F1, F2, F3 represents three different Male and Female speakers, respectively.
Additionally, to compare the proposed speech time reversal strategy with the short-time speech reversal approach, we analysed the spectrographic outputs from both methods as shown in Figure 3. Our analysis revealed that, in the case of complete speech reversal, the harmonic structures are prominently visible, which strongly indicates the retention of speaker-specific information. The clear presence of these harmonic patterns suggests that even though the reversed speech is rendered unintelligible, it preserves critical acoustic cues such as timbre and pitch that are unique to the speaker.

Fig. 3: Spectrographic visualization of (a) original speech (b) 20 ms short-time, (c) 100 ms short-time speech reversal, and (d) complete speech time reversal.
Finally, we perform several subjective and objective evaluations to measure effectiveness of the proposed data augmentation strategy in the context of VC. Table 1 provides a summary of the results, encompassing both subjective and objective assessments.
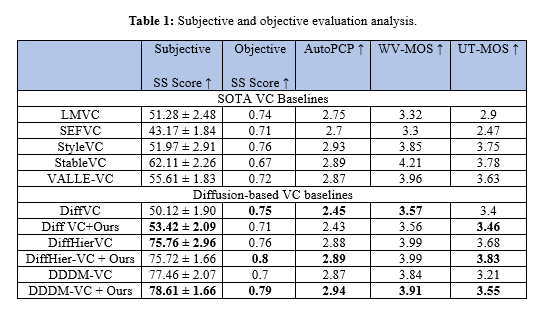
We leverage full-utterance speech time reversal (STR) as a targeted data-augmentation strategy within a diffusion-based voice-conversion pipeline to strengthen speaker embeddings. Whereas earlier efforts have applied reversal only to short segments or portions of the signal, our method inverts the entire utterance. This destroys intelligible linguistic content yet preserves global rhythmic and tonal contours, which, as our perceptual studies show, are alone sufficient to maintain speaker-specific information. This finding supports the fusion of conventional speaker embeddings with those derived from time-reversed speech, providing a robust means to disentangle speaker identity from linguistic content. Our experimental evaluations on the LibriSpeech and VCTK databases, using a diffusion-based voice conversion framework, reveal that the proposed approach significantly improves speaker similarity scores while maintaining high speech quality. These results underscore the potential of STR to overcome data limitations in zero-shot VC scenarios and pave the way for future research to further refine and integrate such unconventional signal transformations into voice conversion systems.
@inproceedings{rewind-vc-2025,
title={REWIND: Speech Time Reversal for Enhancing Speaker Representations in Diffusion-based Voice Conversion },
author={Biyani, Ishan and Shah, Nirmesh and Gudmalwar, Ashishkumar and Wasnik, Pankaj and Shah, Rajiv Ratn},
booktitle={INTERSPEECH},
year={2025}
}
To know more about Sony Research India’s Research Publications, visit the ‘Publications’ section on our ‘Open Innovation’s page: Open Innovation with Sony R&D – Sony Research India
In most of the cases, it has been found that Content Driven sessions outperform the time driven sessions. The results are obtained on 6 baselines: STAMP, NARM, GRU4Rec, CD-HRNN, Tr4Rec on datasets like Movielens (Movies), GoodRead Book, LastFM (Music), Amazon (e-commerce).